Programming assignments are usually considered as the major assessment component of a programming course. Since the programming assignments are usually done using computers, it is very easy for students to copy the source code from each other. Plagiarism in programming has been a serious problem within the years. Also, students may submit their assignments after the due date, so the teacher may have to mark the assignments over a long period of time. They may forget similar scripts they marked before. Moreover, a programming class usually contains a large number of students. So it is very difficult for teachers to find out similar pairs of programs from a large set of programs. Due to the serious problem of plagiarism in programming courses, the main focus of this project is to design and implement a program comparator to detect plagiarism.
Also it is time consuming for the teacher to mark the assignments one by one manually in a large set of programs. As the teacher only needs to check the program with the model answer for most programs, the program comparator can be implement for automatic marking. Most previous program comparing algorithms compare either syntax or semantic only, this is not accurate enough for program comparison. Therefore, an efficient and accurate program comparing tool comparing both syntax and semantic is highly demanded.
The marking of programming assignments involve two processes, accurate plagiarism detection and effective marking of the assignments. This project focuses on the analysis excising program comparing methods and how students carried out plagiarism in order to develop an accurate plagiarism detection tool. Marking of the assignments is a time consuming job. So this project also analyses existing auto marking methods and develop an effective automatic marking tool.
Metric-based is an earlier approach. This is also called attribute-counting-metric since it compares the frequency of keywords between pairs of programs. Different systems use different metrics. For example, the following are some of the metrics used by the Faidhi-Robinson System (Faidhi and Robinson, 1987), number of program statements, repetitive statement percentage, conditional statement percentage, number of modules, module contribution percentage (the number of code lines inside procedures, count of unique identifiers, average spaces percentage per line, average identifier length.
Later on, a more accurate and reliable approach structural-based comparison is developed. The programs are parsed and transformed to token streams. The following shows an example of Java source text and corresponding tokens:
| Java Source Code | Generated Tokens |
|---|
| public class Count{ | BEGINCLASS |
| public static void main(String [] args) | VARDEF,BEGINMETHOD |
| throws java.io.IOException{ | VARDEF,ASSIGN |
| int count = 0 ; | VARDEF,ASSIGN |
| while(System.in.read() != -1) | APPLY,BEGINWHILE |
| count ++; | ASSIGN,ENDWHILE |
| System.out.println(count+” chars.”); | APPLY |
| } | ENDMETHOD |
| } | ENDCLASS |
Tree-based comparing approach is chosen because it can compare both the structure and the content of the programs. Each program is transformed into a parse tree with nodes and tokens. Then, a program comparator is developed. It compares the trees in pairs and produces a similarity score for each pair.
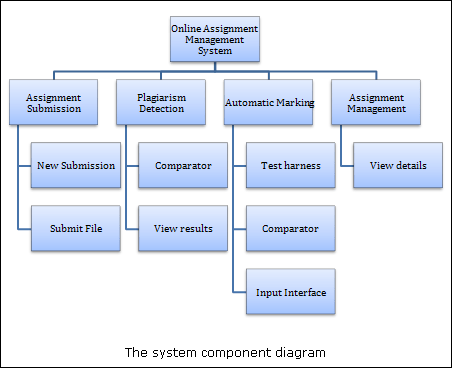
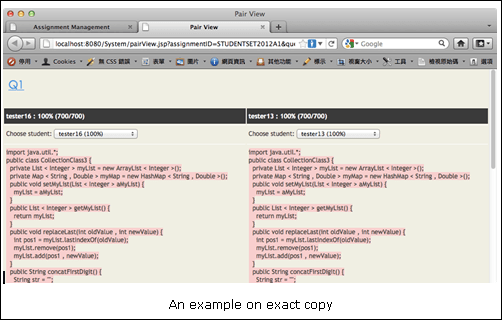
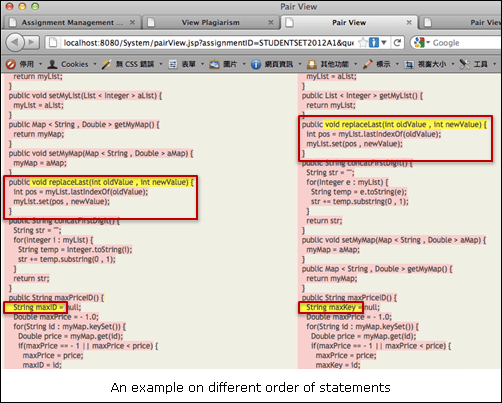
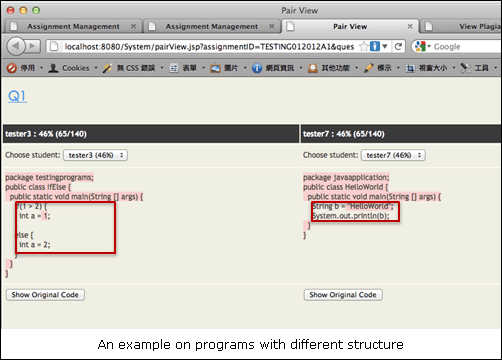
After the comparator is developed, it is applied as a plagiarism detection tool. A threshold rate is defined. If the similarity rate of a pair of programs is higher than the threshold rate, the pair is considered as plagiarized programs. The comparator can also be applied as an automatic marking tool. The more similar they are, the higher the score of the program. An online assignment management system is developed to evaluate the comparator. The system includes managing assignments, checking plagiarism and marking assignments. An example of a simple parse tree is shown below: