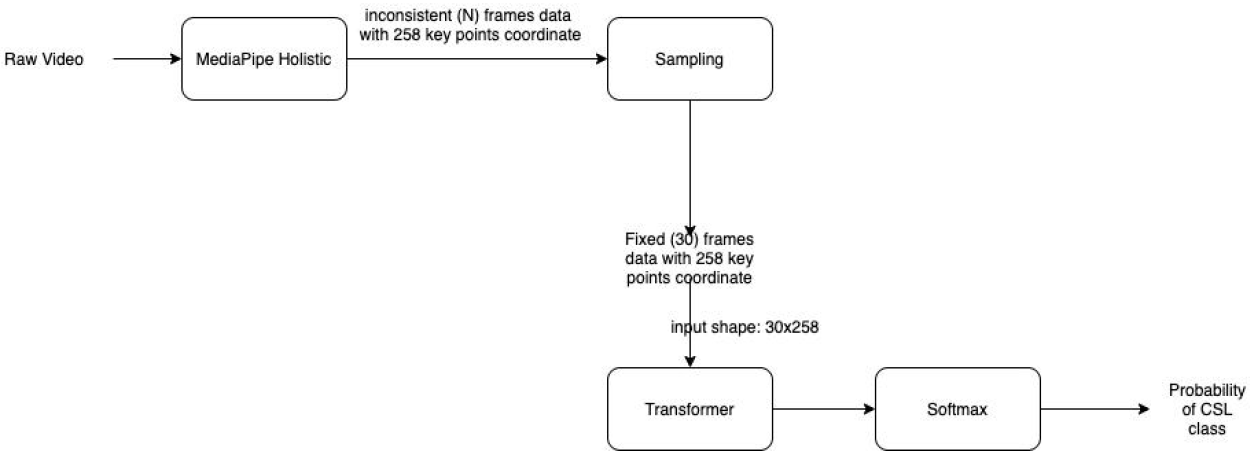
Data preprocessing
Two data preprocessing solutions were used for SLR tasks. The first solution was MediaPipe Holistic, which combined three components to provide real-time detection and tracking of hand, body pose, and facial landmarks. MediaPipe Hands detected and tracked hands, providing 21 3D hand landmarks for each hand. MediaPipe Pose estimated body pose, providing 33 3D landmarks with visibility, including key body joints. MediaPipe Face Mesh detected and tracked facial landmarks, providing 468 3D mesh points representing the face’s geometrical structure.
The second solution was frame sampling strategies for sign language video data. The inconsistency in the number of frames in the sign language videos of the WLASL dataset posed challenges for training models. The project developed several algorithms to standardize the number of frames used for training, with the same sampling strategy currently being applied to both models. Future work could explore various sampling strategies within the same model. These solutions could help improve the accuracy and effectiveness of SLR models.
Transformer with Self-Attention Model for CSLR
The Transformer with Self-Attention model was a neural network that used self-attention to focus on different parts of the input sequence without prior knowledge of the relationships between the elements. In SLR using MediaPipe key points, each frame of the continuous sequence could be represented as a set of key points, with each key point corresponding to a specific joint or feature of the signer’s body pose and hands. The Transformer with Self-Attention could be trained on this input sequence to recognize different sign language gestures or phrases. During inference, the trained model predicted the sign language gesture or phrase for each new input sequence of key points in real-time. The self-attention mechanism allowed the model to adapt to different sign language styles and variations while being robust to noise and other types of input variability.
Experiment
The experiment was conducted on the Word-Level American Sign Language (WLASL) dataset for sign language recognition (SLR). Initially, a custom dataset consisting of three categories with vital facial points was used, but later, the WLASL dataset’s first ten classes were used, and facial key points were excluded from feature selection. The project highlighted the challenges of capturing facial expressions’ impact on SLR accurately and the need to focus on the critical aspects of sign language gestures.
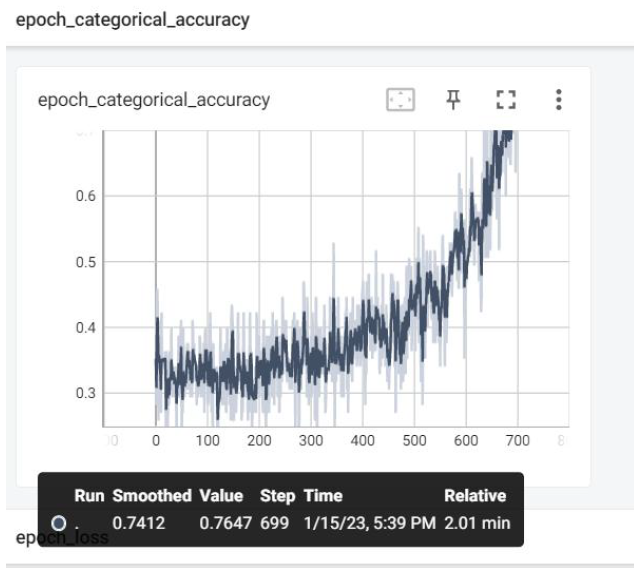
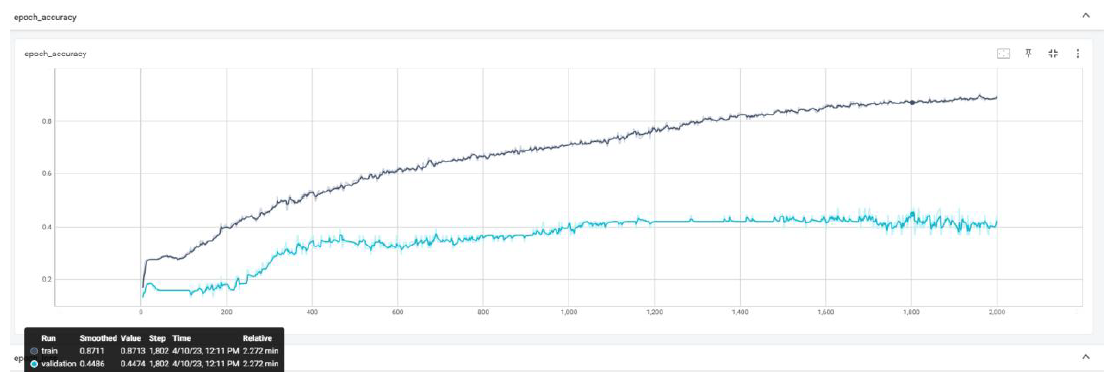
Two models, LSTM and Transformer with Self-Attention, were used for the task of continuous sign language recognition (CSLR). The models were trained and evaluated on benchmark datasets for CSLR, such as the self-recorded three classes and WLASL datasets. The project emphasized the importance of evaluating the models’ stability during the training phase and their robustness to noise. These findings could help improve the accuracy and effectiveness of SLR models and their evaluation on benchmark datasets.
The experiment was conducted on the Word-Level American Sign Language (WLASL) dataset for sign language recognition (SLR). Initially, a custom dataset consisting of three categories with vital facial points was used, but later, the WLASL dataset’s first ten classes were used, and facial key points were excluded from feature selection. The project highlights the challenges of capturing facial expressions’ impact on SLR accurately and the need to focus on the critical aspects of sign language gestures. Two models, LSTM and Transformer with Self-Attention, were used for the task of continuous sign language recognition (CSLR). The models were trained and evaluated on benchmark datasets for CSLR, such as the self-recorded three classes and WLASL datasets. The project emphasizes the importance of evaluating the models’ stability during the training phase and their robustness to noise. These findings can help improve the accuracy and effectiveness of SLR models and their evaluation on benchmark datasets.